
[Python #26] numpyとcupyを比較
はじめまして。
新しくpythonチームに参加しました。A.Sです。
私は現在、愛知県の大学に通っている大学4年生で、情報学を専攻しています。授業で習った知識を生かして何かできたらいいなと思い、インターンに参加しました。
今回は、pythonのライブラリであるnumpyとcupyの紹介をしたいと思います。
Numpy
Numpyは、数値計算を効率的に行うためのライブラリです。多次元配列を扱うための関数が多く用意されています。
インストールにはpipやcondaを使います。
pip install numpy
Cupy
Cupyは、NVIDIA GPUで演算することを前提にした計算ライブラリで、Numpyと高い互換性を持ちます。
NumpyはCPU上での計算に特化している一方で、CupyはGPU上での計算に特化しており、大規模な演算を高速に行うことができます。
なお、cupyを使用するには、NVIDIA GPUが使用できること、CUDAToolkitをインストールしていることなどが必要です。
インストールにはpipやcondaを使います。下はcudaのversionが12.xの場合のコマンド例です。
https://docs.cupy.dev/en/stable/install.html
pip install cupy-cuda12x
比較
まずはnumpyとcupyを、それぞれnp、cpとしてインポートします。
import numpy as np
import cupy as cp続いてサイズの大きい行列(今回は10000×10000)をランダムに生成します。ここで、numpyで計算するものはnumpy.ndarray型、cupyで計算するものはcupy.ndarray型で生成します。
n_array = np.random.random_sample((10000, 10000))
c_array = cp.random.random_sample((10000, 10000))今回は生成した行列の積を計算してその時間を計測してみます。AとBの行列積は、numpy.dot(A, B)とcupy.dot(A, B)で計算することができます。時間の計測にはtimeモジュールを使用しました。
np.dot(n_array, n_array)
cp.dot(c_array, c_array)プログラムの全体は以下の通りです。numpyで行列を生成して積をとるときのコードと、cupyで行列を生成して積をとるときのコードが非常に似ていることが分かると思います。
import numpy as np
import cupy as cp
import time
#大規模な行列の生成
n_array = np.random.random_sample((10000, 10000))
c_array = cp.random.random_sample((10000, 10000))
#numpyを使った計算
s_time = time.time()
np.dot(n_array, n_array)
e_time = time.time()
print(f"numpyでの計算時間: {e_time-s_time}")
#cupyを使った計算
s_time = time.time()
cp.dot(c_array, c_array)
e_time = time.time()
print(f"cupyでの計算時間: {e_time-s_time}")実際に実行してみます。Jupyter notebook上で実行しています。
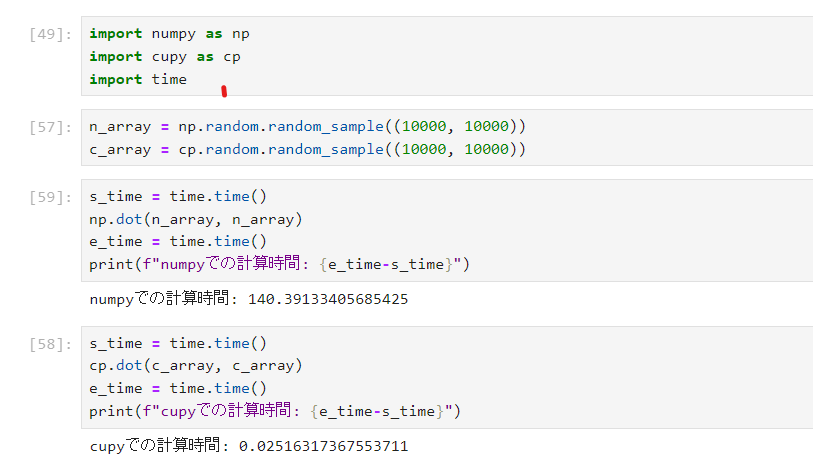
numpyを用いた際の計算には約140秒かかっていますが、cupyを用いた計算には約0.025秒しかかかっていません。
つまり、numpyで計算したものよりcupyで計算したものの方が5000倍以上はやく実行できています。
おわりに
今回はnumpyとcupyについて紹介し、両者について比較を行いました。
cupyを使うことで、簡単にGPUを使った演算が可能になります。
ただ、使っているGPUの性能や使う場面によってはnumpyを使った方が早くなる場合もあるので、気になった方はぜひ調べてみてください。
参考
https://numpy.org/doc/stable/reference/random/generated/numpy.random.rand.html
https://docs.cupy.dev/en/stable/reference/generated/cupy.random.rand.html
