[Python #4] Webスクレイピング
ご無沙汰してます。pythonチームリーダーのH.Iです。
今回はプログラミングを始めると一度は耳にしたことがあるであろう、【Webスクレイピング】についてお話ししたいと思います。
スクレイピングとは
そもそもスクレイピングという言葉は、「こする」「かき集める」という意味をもつ「Scrape」という英単語から来ています。IT用語においてはこの意味が転じて、Webやデータベースを探ってデータや情報を抽出することという意味で用いられます。
しかし、Webスクレイピングという言葉を使うときは上記のような狭い意味でのスクレイピングでは満足に目的を達成することができません。Web上からデータを抽出してくる場合には、広大なネットの海から自分が目的とする情報がどこにあるのかをまず見つけなければなりません。実際には当然ある程度はアタリをつけて行うわけですが、柔軟な探索が必要となってきます。
そのために、事項で説明する「クローリング」という技術が登場します。
クローリングとは
クローリングは、「這いまわる」という意味を持つ「Crawl」という英単語から来ています。Webスクレイピングにおいては、Webページ上を広く巡回することを指します。
実際の作業では、目当てのWebページのサーバーにリクエストを送り、レスポンス(htmlファイルなど)をもらうことでページソースを取得することも含めてクローリングと呼んだりします。
Webスクレイピングとは
もうお分かりのように、Webスクレイピングは、「クローリング」でWeb上を徘徊し、自分の欲しいデータの存在するWebページにたどり着いたのち、「スクレイピング」により欲しいデータを抽出する一連の流れを指すのです。
具体的には、クローリングにより取得したページソースからスクレイピングにより目当てのデータを抽出する作業となります。
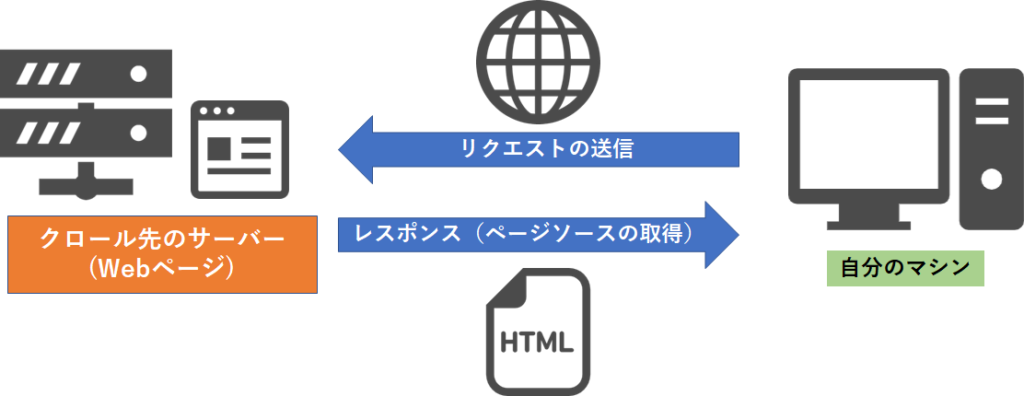
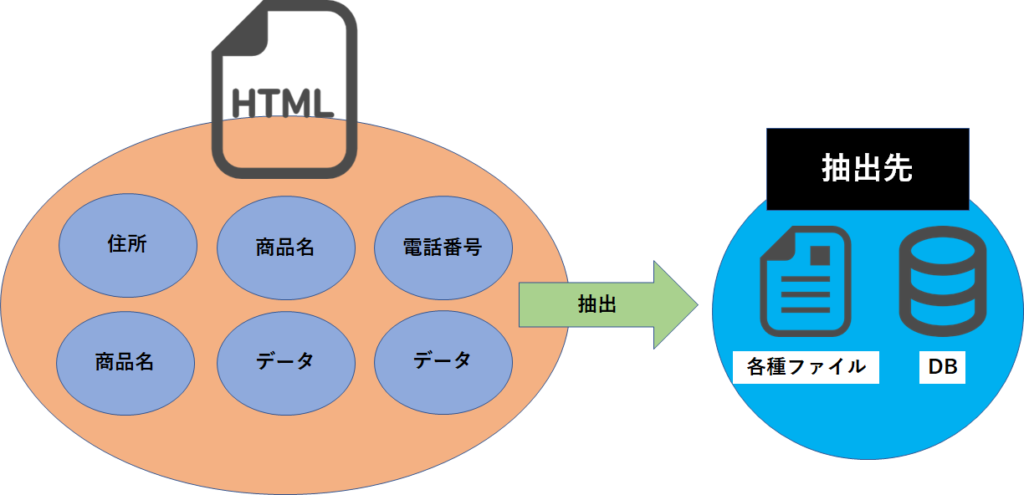
もちろん言葉の定義は使われる文脈により様々なので、必ずしも上記の定義が常に成り立つというわけではありませんので悪しからず。
PythonとWebスクレイピング
みなさんは、普段どれほどネットを使いWebページなどから情報を得るでしょうか。多くの人はGoogleやYahoo!!などの検索エンジンからキーワードを検索し、欲しい情報の載っているページを閲覧することでしょう。
なんという言葉で検索するか、もしくはどのような情報が欲しいのか。これが分かっていれば皆さんが普段行っているような手動でかつ目視で情報をとってくるようなことをする必要はないのです。
そうです。プログラミングで自動化してしまえばよいのです。
PythonにはWebスクレイピングを行うためのライブラリが多く用意されています。
私自身実際の業務でPythonを使い、何か月にもわたり毎日決まった時間にWebスクレイピングを行い、そのデータの処理を行ってきました。一度プログラムを走らせた後はよほどの不具合が起きない限り私が何かする必要はありません。これぞ自動化の醍醐味です。
おわりに
Webスクレイピングについてはなんとなくお分かりいただけたでしょうか。
結構抽象的な説明となってしまいましたが、実際に自身でコードを書いてみるとより理解しやすいかもしれません。
pythonチームでは、pythonを用いたWebスクレイピングのナレッジを蓄積していっています。このナレッジは社内のみでの共有となっているため、このようなBlog記事に載せることは致しません。
もしご興味ある方はぜひ弊社のインターンに応募してください!